
Bandwidth Usage after Ethereum Withdrawals
Observing my staker's network traffic before and after Shapella

On April 12th, Ethereum underwent its Shapella upgrade. This was actually a combination of two separate upgrades: Capella on the consensus layer, and Shanghai on the execution layer. Various features were included in this joint upgrade, but by far the most anticipated was validator withdrawals, which closed the staking loop; once the upgrades went live, all validators with 0x01 type credentials1 became eligible to withdraw stake in one of two ways:
The user can direct their consensus client to exit the validator entirely. This puts the validator into a queue, after which the entire balance of that validator is dispersed to its withdrawal address on the execution layer.
Non-exiting validators automatically “sweep” their balances in excess of 32 ETH2 every 4 days or so3. Emphasis on automatically — users do not need to direct their consensus client to do this and even if they wanted to preserve validator balances they would not be able to.
The first option (exiting) is what closes the staking loop and puts an upper bound on the risk of some disaster befalling a user’s staking box — specifically, the exiting validator is still on the hook for making attestations/proposals until it moves through the queue, the length of which dictates anticipated penalties for a staker that cannot continue operations (e.g. 4 days in the queue = 4 days of offline penalties).4
However, the second option (sweeping) is far more interesting from a network perspective because those messages are continuously being broadcast by every validator on a cycle dictated by the withdrawal queue (different queue than the exit queue).
Shapella added two5 new, continuously broadcasting message types: Withdrawal for consensus and EIP4895 for execution. This means there are two new gossip topics for all nodes on the network and, naturally, we should expect increased bandwidth consumption. But how much?
Data Snapshot Before and After Capella
I run a staking box myself and have system monitoring in place, so I went to see if bandwidth consumption had meaningfully changed after Shapella. I have about a week’s worth of data on either side of the upgrade and the results are pretty noticeable. Each type of data is tracked pre-Capella from April 3-12 and post-Capella from April 12-18. Note that what follows is not an exhaustive analysis, but rather a simple presentation of data.
There are some caveats. First, a cache of BLSToExecutionChange messages — another consensus message type which converts 0x00-type withdrawal credentials to 0x01-type — was unclogged the moment Capella went live, leading to a massive burst in gossip traffic on the consensus layer. Because each validator can only change credentials once, this was an ephemeral state. Second, a mass of exiting validators — mainly from Kraken due to its SEC-settlement-induced withdrawal mandate — was also absorbed by the network, though I don’t think this one was quite as material in terms of traffic spikes.
Overall System Bandwidth
The most important metric is the overall bandwidth used on my staking box. This is a Linux-level measurement and tracks bits flowing through the networking interface, which in my case is ethernet.
Outbound traffic: 8.5Mb/s → 10.41 Mb/s (+22%)
Inbound traffic: 7.19Mb/s → 8.48Mb/s (+18%)

Client Usage
Next I looked at the individual clients (execution and consensus). I use geth for my execution client and lighthouse for consensus. Note that the following charts use kB/s, but I have converted the values to Mb/s to stay consistent with overall system bandwidth usage shown above6.
NOTE: Bandwidth usage for the two clients does not add up to the overall network usage, so clearly there is some other source of traffic that is not showing up in these monitoring views. Regardless, it is interesting to observe relative differences for each client.
Geth
Changes in consensus client bandwidth were a bit strange, as they showed very large average increases, but this is mostly attributable to a few extremely large spikes. I’m not quite sure what to make of these spikes, as they seemed to concentrate near the upgrade (late 4/12 - early 4/13) and have since become more disparate. If you know what’s causing these spikes, please drop a comment!
Inbound traffic: 0.404Mb/s → 0.614Mb/s (+52%)
Outbound traffic: 0.888Mb/s → 1.448Mb/s (+63%)

EDIT: After posting this I thought to check on Ethereum fees over this time range to see if it might strongly correlate to the above spikes in geth traffic. Average fees have been higher since the upgrade, and I think this does explain some of the spikes, but by no means does it explain the large disparity in traffic spikes pre- and post-upgrade.

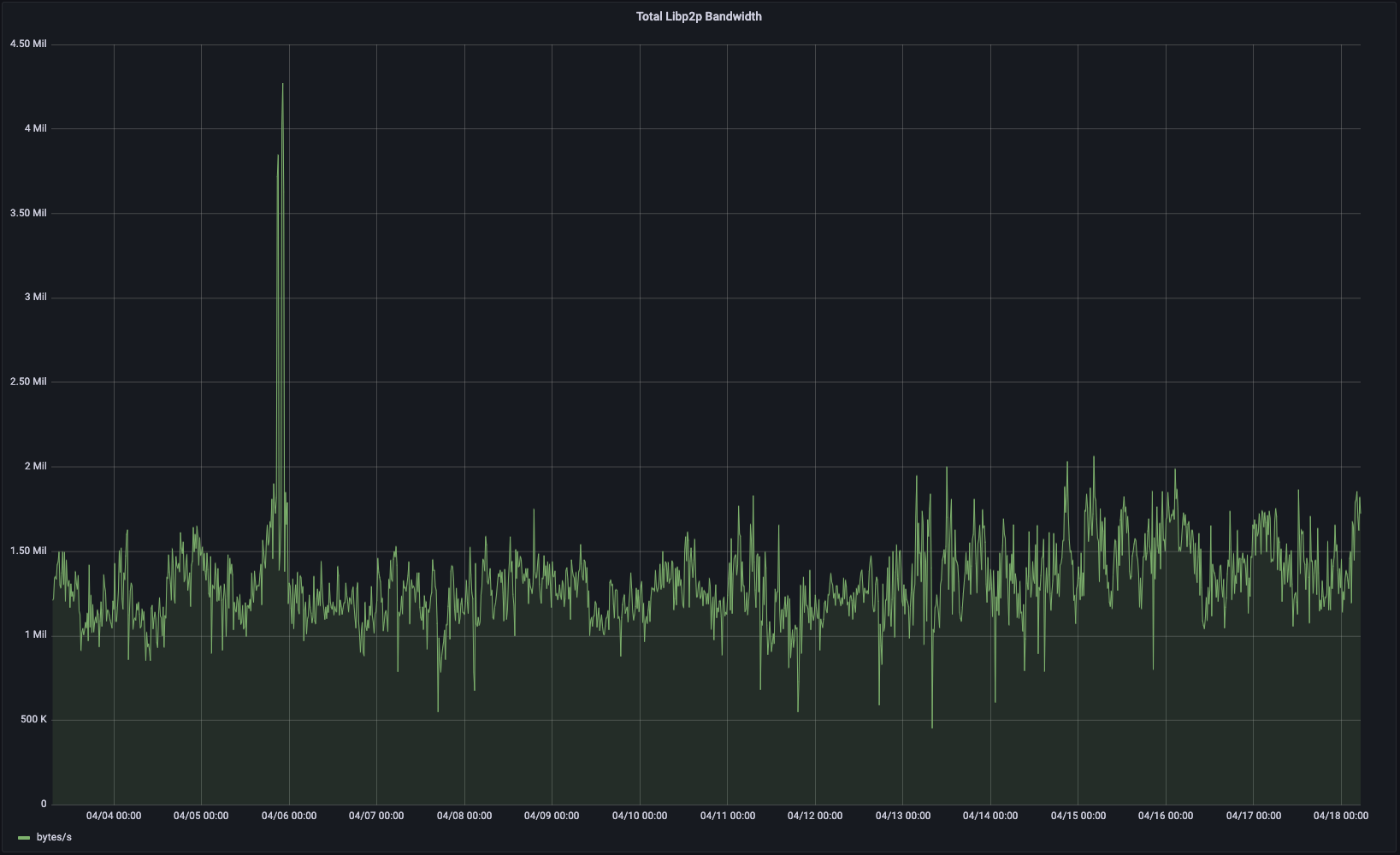
Lighthouse
Unlike the other dashboards, my lighthouse monitor combines inbound and outbound traffic into one view. The results were noticeable, but less dramatic than those of geth. However, like geth, the bandwidth variance increased precipitously after the upgrade went live.
NOTE: This dashboard does not provide numerical averages, so I had to eyeball these numbers based on the chart below.
Combined traffic: ~9.6 Mb/s → ~11.2 Mb/s (+~16.6%)
Drawing a Conclusion
It is too early to get much inference out of this data, but here are some findings from the above charts that I think are worth highlighting:
Overall network traffic did increase significantly: by about 20%. This was expected directionally, but is higher than I would have assumed. Adding new message types to a gossip protocol will always have some effect on traffic.
Both consensus and execution layer bandwidth consumption saw fairly large increases in average traffic (with the execution layer changes being much larger), but saw much larger increases in variance. This variance does not appear to have abated after 6 days of measurements.
Shanghai (the execution upgrade) led to massive spikes in geth network traffic. I’m not sure what caused this behavior, but it’s something to keep an eye on. Note that there have been no large spikes for about 48 hours at this point, so perhaps the large density of these spikes was ephemeral.
It will be interesting to observe where these traffic measurements end up long term.
0x01 type credentials refer to a given validator’s withdrawal address being one on the execution layer, i.e. the typical 20 byte address you would typically use to do anything on Ethereum. Prior to this credential type, all validators had to use type 0x00 credentials, which were BLS public keys typically derived on a path which was associated with the validator key, which is also of BLS variety (specifically on the bls12-381 curve). None of this is terribly important for this article, but at a certain point people started switching to the 0x01 variety because BLS addresses cannot send or receive ETH on the execution layer, which only validators signatures made on the secp256k1 curve. The Capella update also introduced the ability to make a one-time transition (per validator) from 0x00 credentials to 0x01.
This is done because having a balance >32 ETH is wasted capital, as the validator has no greater change of being chosen for a block proposal relative to a 32.0 ETH balance.
The withdrawal queue’s length is dictated by the number of validators in the network. More validators = longer withdrawal queue.
Technically validators could already exit prior to Shapella, but the balance was locked up indefinitely because withdrawals were not enabled. This functionally led to very few validators ever exiting, likely dominated by those who experienced truly unrecoverable meltdowns in their staking setup.
Of course there is a third message added: BLSToExecutionChange for consensus. However, this can only happen once per validator and it is expected that most/all future validators will be created with type 0x01 credentials, so I expect this message’s usage to approach zero over the long term.
For those unfamiliar with unit conversions: k=kilo=1000, M=mega=1000000, b=bit, B=byte=8 bits. So 1000kb = 1Mb and 125kB = 1Mb